Современные неройсети могут не только создавать контент. Теперь они умеют имитировать голоса людей. Благодаря этому, в интернете появился новый тренд: AI-каверы. В них нейросеть исполняет известные песни голосами других артистов. Уже сейчас на YouTube есть более сотни таких треков. Некоторые из них весёлые, другие необычные, а какие-то звучат даже лучше оригиналов. В этой статье расскажем, как работает нейросеть, изменяющая голос в песне, на что она способна, а также рассмотрим самые лучшие сервисы по генерации голоса.
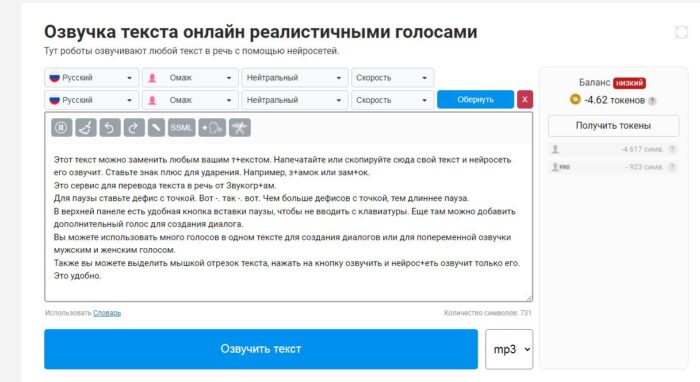
Elevenlabs онлайн нейросеть изменяющая голос в песне
Начнём нашу подборку нейросетей с простого сервиса Elevenlabs, доступного по ссылке https://elevenlabs.io/. Он не умеет петь и заменять голоса в треках, зато отлично справляется с озвучкой любого текста. Это может понадобиться вам для создания видео, презентаций, рекламы и прочего контента с записанным голосом. Теперь больше не нужно нанимать профессионального диктора и платить ему за озвучка готового текста. С этой задачей отлично справляется нейросеть.
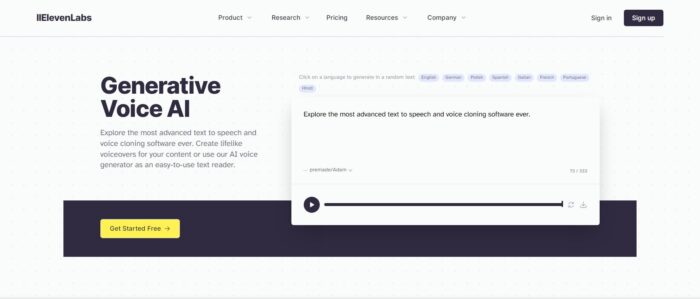
В отличие от многих других нейронных сетей, генерирующих голос, Elevenlabs делает это правдоподобно. Голосовое сообщение, которое вы получите на выходе, не будет отличаться от записанного человеком. Elevenlabs даёт действительно высокое качество записи и правдоподобное звучание. Кроме того, на выбор доступно несколько десятков голосовых моделей, отличающихся по тембру, настроению и эмоциональному окрасу. Поэтому с Elevenlabs вы получите именно тот голос, который вам нужен.
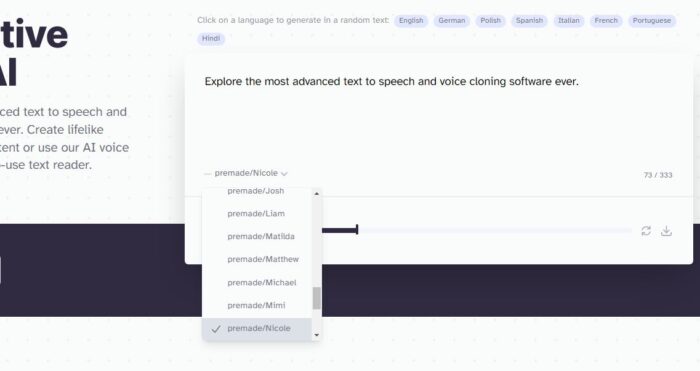
Texttospeech с русской озвучкой
Недостаток прошлого сервиса в том, что он работает только с английским текстом. Если вам нужна русская озвучка, используйте нейронную сеть Texttospeech на сайте https://texttospeech.ru/. Уже сейчас отечественный аналог работает корректно, озвучивая фразы не отличимым от реального голоса. На выбор доступно 20 бесплатный вариантов озвучки и ещё несколько дополнительных голосов при покупке подписки.
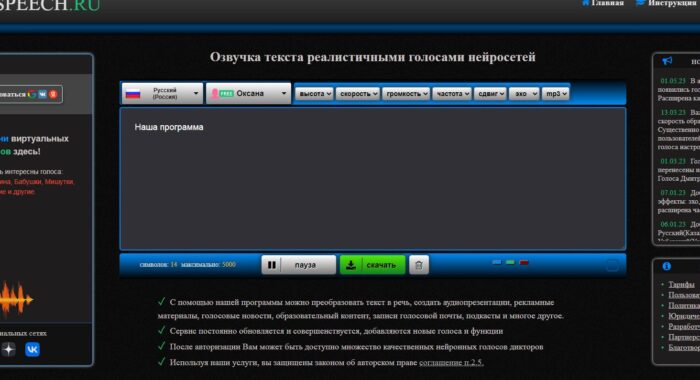
ZVUKOGRAM ещё один синтезатор голоса
ZVUKOGRAM имеет несколько интересных функций. Например, вы можете настроить сервис так, чтобы в итоге из вашего текста получился полноценный диалог. То есть, разные фразы будут озвучены разными голосами, а вам не придётся ничего монтировать. Можно настроить эмоциональный окрас речи диктора, а также скорость произношения. Ещё одна интересная функция – установка ударений при помощи знака «+». Это позволяет добиваться от нейросети расстановки правильных акцентов.
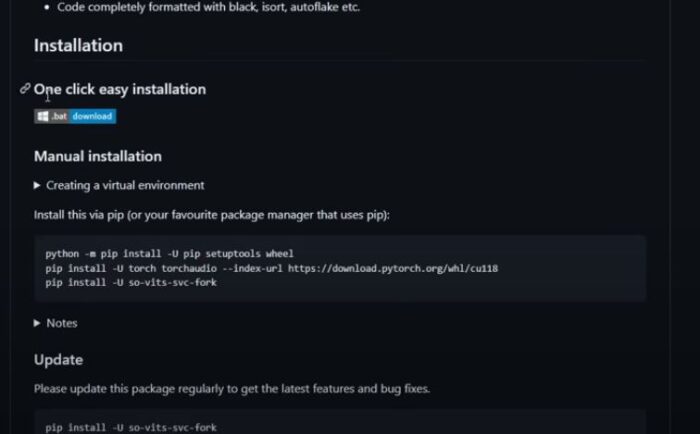
SO-VITS-SVC – это уже более комплексная нейронная сеть, позволяющая изменять голос в песне на другой
SO-VITS-SVC – это одна из популярных нейросетей, при помощи которых сейчас делают AI-каверы. Для начала вам понадобится скачать саму программу по ссылке: https://github.com/voicepaw/so-vits-svc-fork. Прокрутите страницу вниз до раздела «Installation» и нажмите на кнопку «.bat download». После этого запустите скачанный файл.
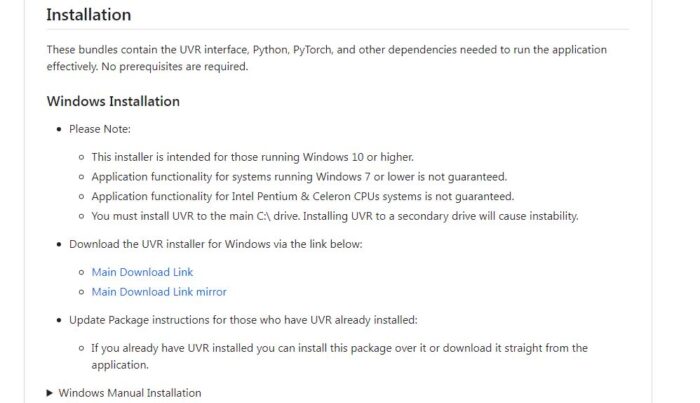
Теперь вам понадобится установить ещё одну нейросеть, доступную по ссылке https://github.com/Anjok07/ultimatevocalremovergui. Она нужна, чтобы удалять вокальную партию из песни, в которой нужно преобразовать голос. Спуститесь вниз до раздела «Installation» и выберите пункт «Main Download Link». После этого установите на компьютер скачанный файл.
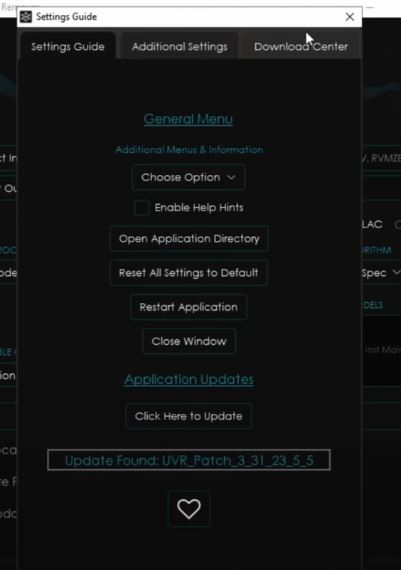
После этого запустите UVR и перейдите в раздел с настройками. Там выберите «Download Center» и скачайте модель «Kim Vocal». Когда она будет скачана переходите в главное меню и загружайте песню, которую хотите обработать. Запускайте программу и ждите, пока она закончит удаление вокала.
Теперь перейдите в папку с SO-VITS-SVC, откройте папку «Scripts» и пролистайте её вниз, пока не найдёте «svcg-gui.exe». Запустите его.
Перед переходом к дальнейшему этапу вам понадобится скачать голосовую модель исполнителя, при помощи которой будет генерироваться голос. Люди сами создают их, тренируя нейронные сети на десятках песен артистов. Большое количество готовых моделей доступно в интернете бесплатно. Например, по этой ссылке вы можете скачать архив с моделью Morgenstern:
Также читайте: Как видит меня нейросеть онлайн по фото бесплатно.
В открывшемся окне программы установите настройки, как на скриншоте ниже. Вы можете сами экспериментировать с ними для достижения наилучшего результата.
Обязательны к заполнению следующие пункты:
- Modelpatch: прикрепите скачанную голосовую модель нужного исполнителя;
- Configpatch: прикрепите второй файл из папки с голосовой моделью;
- File: выберите акапелла-версию песни, которую вы создали в другой программе;
- Pitch: рекомендуется устанавливать на 0, чтобы избежать искажения звука и потери качества.
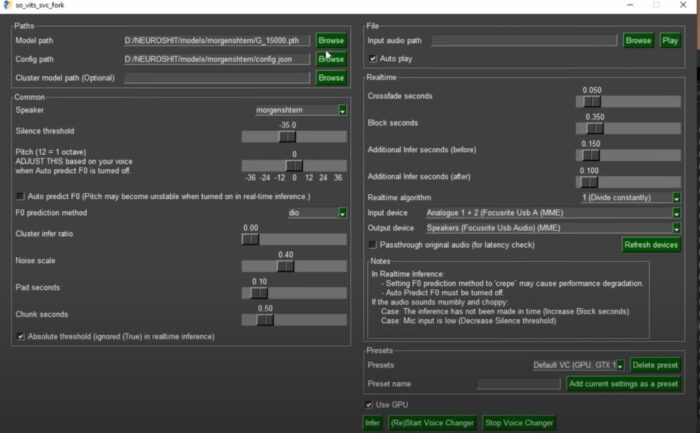
После установки настроек нажмите на «Infer» и дождитесь окончания генерации голоса. Когда она закончится, в папке с нейросетью появится готовый файл формата .wav. Далее вам понадобится открыть программу для написания музыки, например, FL Studio. В неё загрузите две составляющие песни: голос и минус, совместите их и сохраните проект. В итоге вы получите трек, спетый голосом другого исполнителя.
Смотрите видео с подборкой других нейросетей, умеющих петь: